认识到微服务开发的复杂性
- 本地开发要有一个好的开发机器,糟糕的开发机器将会导致糟糕的开发实践
- 确保所有服务都使用构建工具,能在一台新机器上构建整个应用程序,而不需要进行太多配置,让开发人员能轻松地在本地运行应用程序的各个部分
- 使用Kubernetes,利用Telepresence以便轻松调试 Kubernetes 集群中的应用程序
如果对微服务开发的复杂性缺乏理解,那么团队速度将会随着时间的推移而下降
及时将库和工具更新到最新版
所有服务的依赖项版本保持同步,为依赖升级创建技术债务项,并应作为会议的一部分加以讨论,并定期予以解决,将所有依赖项更新到最新版本
不止包括升级依赖包的版本,还包括架构修正,如当引入一个新工具时,可能可以替换掉原先多个工具,有助于降低复杂性
几年前,许多团队开始将 Spring Cloud Netflix OSS 项目用于微服务。他们使用像 Kubernetes 这样的容器编排工具,但是因为是从 Netflix OSS 开始的,所以他们没有使用 Kubernetes 提供的所有功能。当 Kubernetes 内置了服务发现时,他们仍然使用 Eureka 作为服务发现
避免使用共享服务来做本地开发
举例共享数据库
- 一个开发人员可以删除其他开发人员为他们工作编写的数据
- 开发人员害怕实验,因为他们的工作会影响其他团队成员
- 很难单独测试更改。你的集成测试将变得不可靠,从而进一步降低开发速度
- 容易出现不一致和不可预测的状态,开发人员希望在表是空的时候测试边缘情况,但其他开发人员需要一个表来记录
- 只有共享数据库拥有系统工作所需的所有数据,团队成员失去了更改的可追溯性
- 如果未连接到网络,就很难开展工作
它也可以是消息队列、集中缓存(如 Redis)或任何其他可以发生改变的服务
代码托管平台的可见性
在托管平台按产品、服务对微服务进行分组,方便了解代码库结构
服务有明确定义
避免拆分过多服务,会导致管理成本直线上升,
应用单一责任原则(Single Responsibility Principle)来了解微服务是否变得过大,做的事情是否过多
任何服务都不应该直接与其他服务的数据库通信
服务通信是微服务系统性能低下的首要原因: 如果两条信息相互依赖,那么它们应该属于同一个服务,服务的自然边界应该是其数据的自然边界
明确代码重用策略
对处理相同问题的代码,使用包封装,发布在包管理平台,并通过构建工具来让依赖的微服务及时更新
没有适合的工具和自动化的情况下,使用微服务会导致灾难
多语言编程设计
如果你的开发人员还不够成熟的话,那么无论你使用什么编程语言,你开发的都将是糟糕的产品
一个组织可以指定2、3个语言列表,并列出语言的优势
在选择一门语言前,应该考虑以下一些问题:
- 找到成熟的开发人员有多容易
- 重新培训开发人员掌握新技术有多容易?我们发现 Java 开发人员可以相对容易地学习 Golang。
- 代码的可读、可维护性
- 就工具和库的方面而言,生态系统有多成熟?
不仅仅局限于编程语言,也适用于数据库领域, 要始终考虑使用多种技术的维护和操作方面
人员的依赖性
大多数团队专注于他们的特定服务,因此他们并不了解完整的生态系统
确保所有团队都有一个架构团队的代表,使每个团队与整个架构的路线图和目标保持一致(人月神话中有提过,外科手术团队,只需要协调各团队中的架构师)
维护文档
需要维护的文档:
- 设计文档
- C4 模型中的上下文和容器图
- 以架构决策记录的形式跟踪关键架构决策
- 开发人员入门指南
在Gitlab中维护所有的文档
功能不要超过平台成熟度
微服务要比传统的单体式应用更为复杂
需要考虑分布式跟踪、可观察性、混沌测试、函数调用与网络调用、服务间通信的安全服务、可调试性等等。这需要在构建正确的平台和工具团队方面付出认真的努力和投资
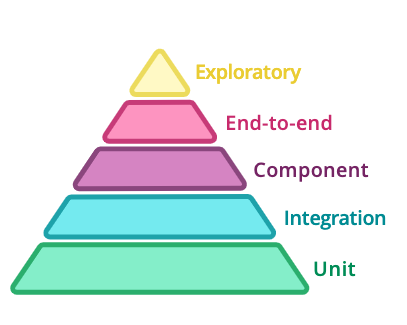
自动化测试
微服务架构为测试地点和测试方式提供了更多选择
微服务测试的金字塔