原因
- 存在一些耗时较长的运算,需要从web服务中移出,比如缓存计算、报表导出
- 管控力度:原先的运算集群采用mq通信方式,master对worker的管控力度不够,会出现一个任务重复失败拖垮集群的现象
- worker之前不能区分,原因还是没有直接由master派发任务,也无法做跨语言调度
目标
master
- 稳定、高可用,不执行具体运算
- 接收、记录待执行的任务,按任务优先级派发,记录任务执行结果,支持超时、重试、失败状态
- 能管控worker生命,知道它的运行状态和任务进度,根据worker状态派发任务
- 向业务方通知运行结果
worker
- 启动时向master注册自己的环境和算力
- 定时汇报自己的运行状态
- 支持多语言
实现
通信
基于grpc的stream方式通信,worker端目前采用重启方式重连,master端可通过end事件清除失效worker
|
|
master和worker的结构
- 基于egg,风格结构与后端业务框架基本相同
- 主要分为job和life_cycle,分管任务和生命周期
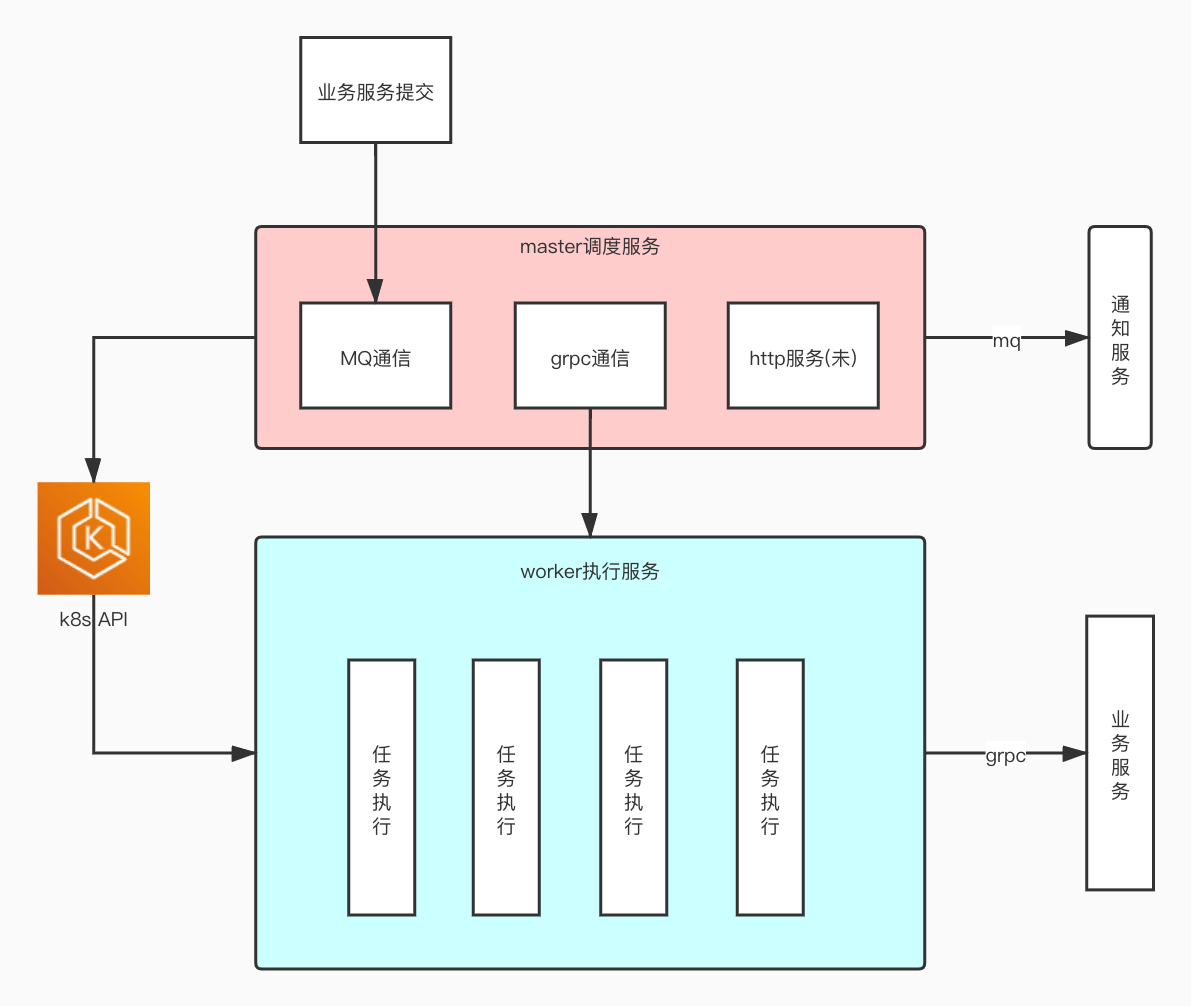
master
- 通过mq记录任务,并定期读取任务到缓存,按优先级排序,
- 处理worker连接,定期检查连接情况
- 派发任务,只在新worker连接和任务完成时执行,定期检查任务执行状态
worker
- 接受master派发的任务调用本地service/method执行,在表中记录执行结果
- 定期自检健康发送心跳给master
使用
任务代码的编写
- 在worker端实现
- 代码位置在service文件夹
|
|
代码结构与业务框架一致,业务数据通过rpc获取,原则上不直连业务数据库
业务服务调用任务
- sdk直接写在fgrid-middleware
调用方式和rpc调用类似
|
|
计划实现功能
- master高可用
- worker多语言版和算力等属性
- 定时任务